Tidy Tuesday Customs and Border Protection
By Steve Ewing in tidy tuesday
November 26, 2024
This weeks Tidy Tuesday data is from the Customs and Border Protection. The data is available from 2020 to present. The data is available from the CBP website. It was written up first for the Tidy Tuesday blog by Tony Galvan here.
“Encounter data includes U.S. Border Patrol Title 8 apprehensions, Office of Field Operations Title 8 inadmissibles, and all Title 42 expulsions for fiscal years 2020 to date. Data is available for the Northern Land Border, Southwest Land Border, and Nationwide (i.e., air, land, and sea modes of transportation) encounters.
Data is extracted from live CBP systems and data sources. Statistical information is subject to change due to corrections, systems changes, change in data definition, additional information, or encounters pending final review. Final statistics are available at the conclusion of each fiscal year.” - CBP
library(tidyverse)
library(janitor)
cbp_resp <- bind_rows(
read_csv("https://www.cbp.gov/sites/default/files/assets/documents/2023-Nov/nationwide-encounters-fy20-fy23-aor.csv", show_col_types = FALSE),
read_csv("https://www.cbp.gov/sites/default/files/2024-10/nationwide-encounters-fy21-fy24-aor.csv", show_col_types = FALSE)
) |>
janitor::clean_names() |>
unique()
cbp_state <- bind_rows(
read_csv("https://www.cbp.gov/sites/default/files/assets/documents/2023-Nov/nationwide-encounters-fy20-fy23-state.csv", show_col_types = FALSE),
read_csv("https://www.cbp.gov/sites/default/files/2024-10/nationwide-encounters-fy21-fy24-state.csv", show_col_types = FALSE)
) |>
janitor::clean_names() |>
unique()
Data exploration
cbp_resp |>
glimpse()
## Rows: 68,815
## Columns: 12
## $ fiscal_year <dbl> 2020, 2020, 2020, 2020, 2020, 2020, 2020, 2020,…
## $ month_grouping <chr> "FYTD", "FYTD", "FYTD", "FYTD", "FYTD", "FYTD",…
## $ month_abbv <chr> "APR", "APR", "APR", "APR", "APR", "APR", "APR"…
## $ component <chr> "Office of Field Operations", "Office of Field …
## $ land_border_region <chr> "Northern Land Border", "Northern Land Border",…
## $ area_of_responsibility <chr> "Boston Field Office", "Boston Field Office", "…
## $ aor_abbv <chr> "Boston", "Boston", "Boston", "Boston", "Boston…
## $ demographic <chr> "FMUA", "FMUA", "Single Adults", "Single Adults…
## $ citizenship <chr> "BRAZIL", "CANADA", "CANADA", "CANADA", "CHINA,…
## $ title_of_authority <chr> "Title 8", "Title 8", "Title 42", "Title 8", "T…
## $ encounter_type <chr> "Inadmissibles", "Inadmissibles", "Expulsions",…
## $ encounter_count <dbl> 3, 1, 2, 239, 1, 0, 1, 6, 1, 1, 1, 18, 52, 1, 2…
encounter_type (character) - The category of encounter based on Title of Authority and component (Title 8 for USBP = Apprehensions; Title 8 for OFO = Inadmissibles; Title 42 = Expulsions)
table(cbp_resp$encounter_type)
##
## Apprehensions Expulsions Inadmissibles
## 22137 9638 37040
component (character) - Which part of CBP was involved in the encounter (“Office of Field Operations” or “U.S. Border Patrol”)
table(cbp_resp$component)
##
## Office of Field Operations U.S. Border Patrol
## 40483 28332
title_of_authority (character) - The authority under which the noncitizen was processed (Title 8: The standard U.S. immigration law governing the processing of migrants, including deportations, asylum procedures, and penalties for unauthorized border crossings. Title 42: A public health order used during the COVID-19 pandemic to rapidly expel migrants at the border without standard immigration processing, citing health concerns.)
table(cbp_resp$title_of_authority)
##
## Title 42 Title 8
## 9638 59177
What is this month grouping?
table(cbp_resp$month_grouping)
##
## FYTD
## 68815
Who did they use the title 42 expulsion power on?
library(kableExtra)
##
## Attaching package: 'kableExtra'
## The following object is masked from 'package:dplyr':
##
## group_rows
expulsions <- cbp_resp %>%
filter(title_of_authority == "Title 42") %>%
group_by(citizenship, fiscal_year) %>%
summarise(total = sum(encounter_count), .groups = "drop") %>%
pivot_wider(names_from = fiscal_year, values_from = total, names_prefix = "FY ") %>%
arrange(desc(`FY 2023`)) %>%
mutate(across(starts_with("FY"), ~ format(., big.mark = ",", scientific = FALSE)))
expulsions %>%
kbl(
caption = "Title 42 Expulsions by Citizenship and Fiscal Year",
format = "html",
digits = 0
) %>%
kable_styling(
bootstrap_options = c("striped", "hover", "condensed", "responsive"),
full_width = TRUE,
font_size = 12
) %>%
add_header_above(c(" " = 1, "Fiscal Years" = ncol(expulsions) - 1)) %>%
column_spec(1, width = "10em", bold = TRUE) %>%
column_spec(2:ncol(expulsions), width = "8em")
| citizenship | FY 2020 | FY 2021 | FY 2022 | FY 2023 |
|---|---|---|---|---|
| MEXICO | 157,952 | 582,813 | 693,044 | 349,685 |
| GUATEMALA | 15,161 | 173,679 | 154,302 | 63,098 |
| HONDURAS | 17,041 | 167,388 | 134,095 | 54,452 |
| VENEZUELA | 49 | 1,283 | 707 | 38,853 |
| EL SALVADOR | 5,946 | 56,769 | 56,322 | 21,132 |
| ECUADOR | 2,245 | 54,683 | 1,155 | 14,429 |
| COLOMBIA | 56 | 1,069 | 12,327 | 13,108 |
| OTHER | 1,095 | 5,532 | 13,567 | 7,208 |
| CUBA | 4,751 | 7,229 | 4,905 | 4,085 |
| INDIA | 310 | 1,012 | 5,133 | 4,072 |
| NICARAGUA | 370 | 3,293 | 4,158 | 3,064 |
| PERU | 50 | 1,063 | 922 | 2,789 |
| CANADA | 538 | 1,822 | 3,339 | 760 |
| CHINA, PEOPLES REPUBLIC OF | 95 | 318 | 1,401 | 671 |
| BRAZIL | 268 | 2,587 | 5,017 | 484 |
| HAITI | 751 | 10,211 | 12,358 | 349 |
| PHILIPPINES | 33 | 107 | 336 | 334 |
| UKRAINE | 7 | 21 | 390 | 190 |
| RUSSIA | 22 | 69 | 163 | 129 |
| ROMANIA | 40 | 98 | 188 | 99 |
| TURKEY | 3 | 25 | 131 | 93 |
| MYANMAR (BURMA) | NA | 4 | 6 | NA |
What did the inadmissibles look like?
inadmissibles <- cbp_resp |>
filter(title_of_authority == "Title 8", encounter_type == "Inadmissibles") |>
group_by(citizenship, fiscal_year) |>
summarise(total = sum(encounter_count), .groups = "drop") |>
pivot_wider(names_from = fiscal_year, values_from = total, names_prefix = "FY ") %>%
arrange(desc(`FY 2023`)) %>%
mutate(across(starts_with("FY"), ~ format(., big.mark = ",", scientific = FALSE)))
inadmissibles %>%
kbl(
caption = "Title 8 Inadmissibles by Citizenship and Fiscal Year",
format = "html",
digits = 0
) %>%
kable_styling(
bootstrap_options = c("striped", "hover", "condensed", "responsive"),
full_width = TRUE,
font_size = 12
) %>%
add_header_above(c(" " = 1, "Fiscal Years" = ncol(inadmissibles) - 1))
| citizenship | FY 2020 | FY 2021 | FY 2022 | FY 2023 | FY 2024 |
|---|---|---|---|---|---|
| HAITI | 739 | 2,508 | 25,566 | 161,155 | 218,007 |
| OTHER | 42,112 | 37,392 | 75,094 | 142,570 | 134,973 |
| MEXICO | 47,452 | 44,790 | 59,053 | 138,236 | 161,877 |
| VENEZUELA | 3,246 | 2,652 | 1,917 | 132,880 | 178,850 |
| UKRAINE | 7,672 | 9,315 | 96,396 | 101,543 | 78,557 |
| CUBA | 4,038 | 805 | 1,307 | 78,833 | 203,929 |
| PHILIPPINES | 45,815 | 46,235 | 54,769 | 51,043 | 48,381 |
| RUSSIA | 5,895 | 12,663 | 30,899 | 49,641 | 20,526 |
| INDIA | 18,356 | 27,088 | 40,336 | 49,497 | 50,681 |
| CANADA | 20,224 | 20,504 | 43,727 | 43,784 | 44,783 |
| NICARAGUA | 999 | 837 | 953 | 40,846 | 57,815 |
| HONDURAS | 2,737 | 11,532 | 15,231 | 34,758 | 32,621 |
| CHINA, PEOPLES REPUBLIC OF | 17,019 | 22,834 | 24,376 | 27,920 | 40,725 |
| COLOMBIA | 2,366 | 4,452 | 5,536 | 12,668 | 22,508 |
| BRAZIL | 2,084 | 1,166 | 5,618 | 10,542 | 5,798 |
| EL SALVADOR | 1,018 | 3,170 | 4,352 | 9,305 | 11,409 |
| GUATEMALA | 1,408 | 4,541 | 4,174 | 7,747 | 10,914 |
| MYANMAR (BURMA) | 3,061 | 3,836 | 4,462 | 4,253 | 4,993 |
| TURKEY | 2,499 | 3,597 | 3,980 | 3,425 | 2,678 |
| PERU | 1,643 | 2,012 | 2,650 | 3,422 | 5,195 |
| ECUADOR | 871 | 1,028 | 832 | 3,391 | 7,584 |
| ROMANIA | 1,120 | 1,015 | 1,245 | 1,187 | 1,019 |
What did the apprehensions look like?
apprehensions <- cbp_resp |>
filter(title_of_authority == "Title 8", encounter_type == "Apprehensions") |>
group_by(citizenship, fiscal_year) |>
summarise(total = sum(encounter_count), .groups = "drop") |>
pivot_wider(names_from = fiscal_year, values_from = total, names_prefix = "FY ") %>%
arrange(desc(`FY 2023`)) %>%
mutate(across(starts_with("FY"), ~ format(., big.mark = ",", scientific = FALSE)))
apprehensions %>%
kbl(
caption = "Title 8 Apprehensions by Citizenship and Fiscal Year",
format = "html",
digits = 0
) %>%
kable_styling(
bootstrap_options = c("striped", "hover", "condensed", "responsive"),
full_width = TRUE,
font_size = 12
) %>%
add_header_above(c(" " = 1, "Fiscal Years" = ncol(apprehensions) - 1))
| citizenship | FY 2020 | FY 2021 | FY 2022 | FY 2023 | FY 2024 |
|---|---|---|---|---|---|
| MEXICO | 103,826 | 47,136 | 70,960 | 248,016 | 506,211 |
| VENEZUELA | 1,225 | 46,564 | 186,896 | 163,181 | 134,646 |
| GUATEMALA | 32,867 | 106,071 | 74,585 | 151,004 | 196,057 |
| OTHER | 4,266 | 14,433 | 48,667 | 149,797 | 132,602 |
| COLOMBIA | 346 | 4,974 | 113,108 | 141,612 | 112,168 |
| HONDURAS | 23,579 | 142,229 | 65,649 | 126,818 | 111,752 |
| CUBA | 5,226 | 31,269 | 218,395 | 117,369 | 13,686 |
| ECUADOR | 9,776 | 41,363 | 22,949 | 99,667 | 116,439 |
| NICARAGUA | 1,795 | 46,592 | 159,489 | 94,819 | 33,234 |
| PERU | 391 | 2,102 | 49,616 | 71,991 | 34,005 |
| INDIA | 1,217 | 2,562 | 18,458 | 43,348 | 39,734 |
| EL SALVADOR | 10,749 | 39,524 | 37,123 | 32,409 | 45,798 |
| CHINA, PEOPLES REPUBLIC OF | 1,281 | 319 | 1,979 | 24,109 | 37,976 |
| BRAZIL | 6,795 | 54,306 | 46,386 | 21,466 | 26,332 |
| TURKEY | 78 | 1,367 | 15,359 | 15,468 | 10,633 |
| RUSSIA | 29 | 508 | 5,209 | 7,393 | 1,365 |
| ROMANIA | 326 | 4,046 | 5,978 | 2,406 | 1,529 |
| HAITI | 3,801 | 36,008 | 18,672 | 2,277 | 2,791 |
| CANADA | 75 | 45 | 60 | 156 | 262 |
| UKRAINE | 9 | 42 | 591 | 82 | 48 |
| PHILIPPINES | 7 | 11 | 12 | 22 | 40 |
| MYANMAR (BURMA) | 1 | 1 | 2 | 4 | 11 |
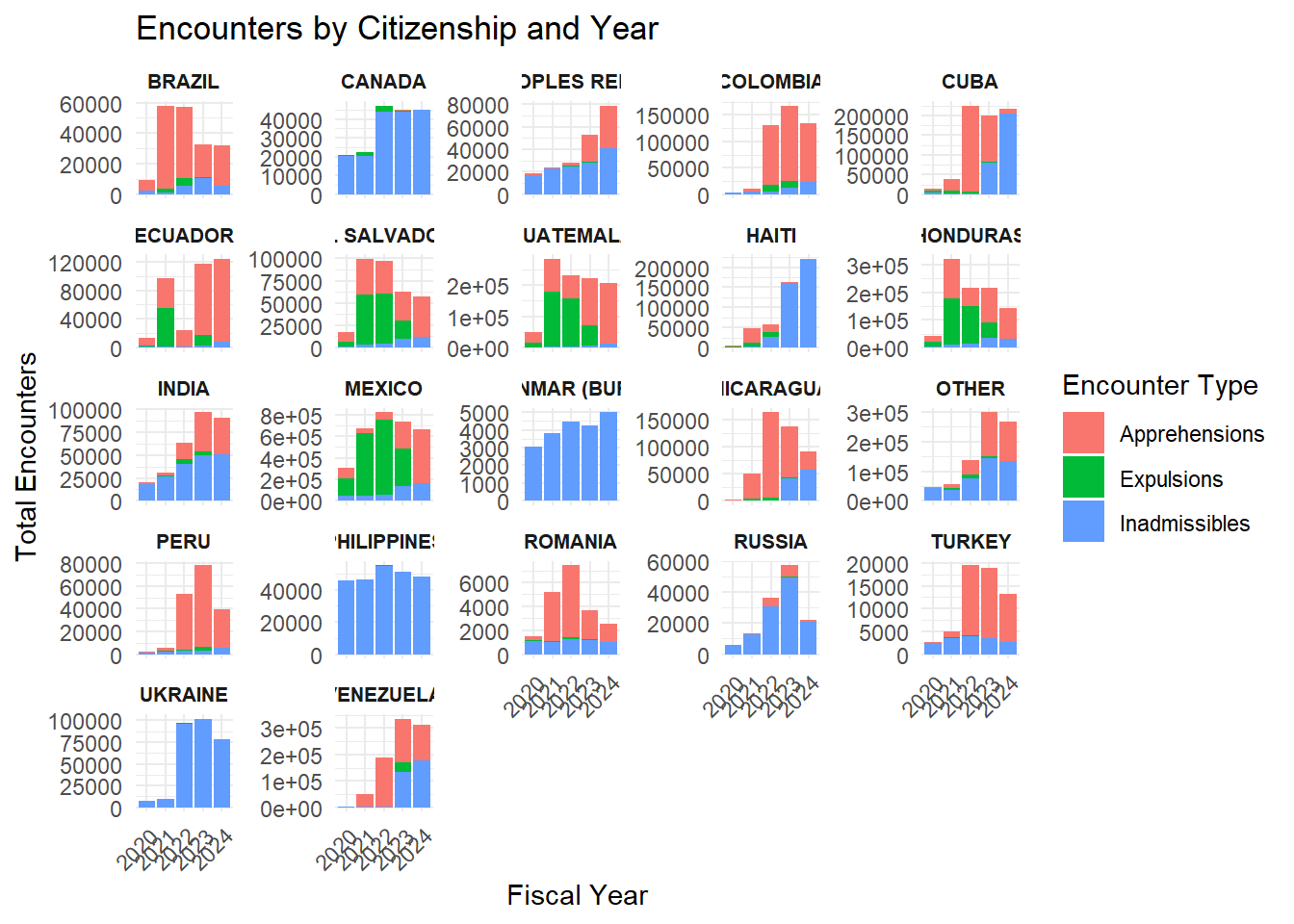
Make a facet plot of the data.
plot_data <- cbp_resp %>%
group_by(citizenship, fiscal_year, encounter_type) %>%
summarise(total = sum(encounter_count, na.rm = TRUE), .groups = 'drop') %>%
mutate(fiscal_year = as.factor(fiscal_year))
ggplot(plot_data, aes(x = fiscal_year, y = total, fill = encounter_type)) +
geom_bar(stat = "identity", position = "stack") +
facet_wrap(~ citizenship, scales = "free_y") +
labs(
title = "Encounters by Citizenship and Year",
x = "Fiscal Year",
y = "Total Encounters",
fill = "Encounter Type"
) +
theme_minimal() +
theme(
strip.text = element_text(size = 8, face = "bold"),
axis.text.x = element_text(angle = 45, hjust = 1)
)
library(ggplot2)
library(dplyr)
library(maps)
##
## Attaching package: 'maps'
## The following object is masked from 'package:purrr':
##
## map
library(grid)
library(sf)
## Linking to GEOS 3.12.2, GDAL 3.9.3, PROJ 9.4.1; sf_use_s2() is TRUE
# Get world map data and convert to sf object
world_map <- map_data("world")
world_sf <- st_as_sf(map("world", plot = FALSE, fill = TRUE))
# Create a data frame of unique country centroids for positioning the bar charts
country_coords <- world_map %>%
group_by(region) %>%
summarise(
long = mean(range(long)),
lat = mean(range(lat))
) %>%
rename(citizenship = region)
# Merge plot data with country coordinates
plot_data_coords <- plot_data %>%
inner_join(country_coords, by = "citizenship")
# Create a base world map using ggplot2
world_base <- ggplot() +
geom_sf(data = world_sf, fill = "lightgray", color = "white") +
theme_void() +
labs(
title = "Title 42 Encounters by Citizenship and Year",
subtitle = "Country-specific encounters visualized as bar charts over each country"
) +
coord_sf()
# Debugging Step: Plot text labels for each country to verify coordinates
world_base <- world_base +
geom_text(
data = plot_data_coords,
aes(x = long, y = lat, label = citizenship),
size = 3, color = "red"
)
# Plot the world base map with text labels to verify coordinates
print(world_base)
# After verifying coordinates, proceed with adding bar charts
# Add bar charts for each country using annotation_custom()
for (country in unique(plot_data_coords$citizenship)) {
# Filter data for each country
country_data <- plot_data_coords %>% filter(citizenship == country)
# Create a mini bar plot for each country
mini_bar <- ggplot(country_data, aes(x = fiscal_year, y = total, fill = encounter_type)) +
geom_bar(stat = "identity", position = "stack") +
theme_void() +
theme(
legend.position = "none",
axis.text = element_blank(),
axis.ticks = element_blank(),
plot.margin = margin(0, 0, 0, 0)
) +
scale_y_continuous(limits = c(0, max(country_data$total) * 1.1)) # Scale y to be proportional
# Convert the mini bar plot into a grob object
mini_bar_grob <- ggplotGrob(mini_bar)
# Get the longitude and latitude for placing the mini bar
country_long <- country_data$long[1]
country_lat <- country_data$lat[1]
# Add the mini bar plot to the world map
world_base <- world_base +
annotation_custom(
grob = mini_bar_grob,
xmin = country_long - 5,
xmax = country_long + 5,
ymin = country_lat - 5,
ymax = country_lat + 5
)
}
# Print the final map with bar charts
print(world_base)
- Posted on:
- November 26, 2024
- Length:
- 9 minute read, 1707 words
- Categories:
- tidy tuesday
- Tags:
- R tidy tuesday